Destroying networks for fun (and profit)

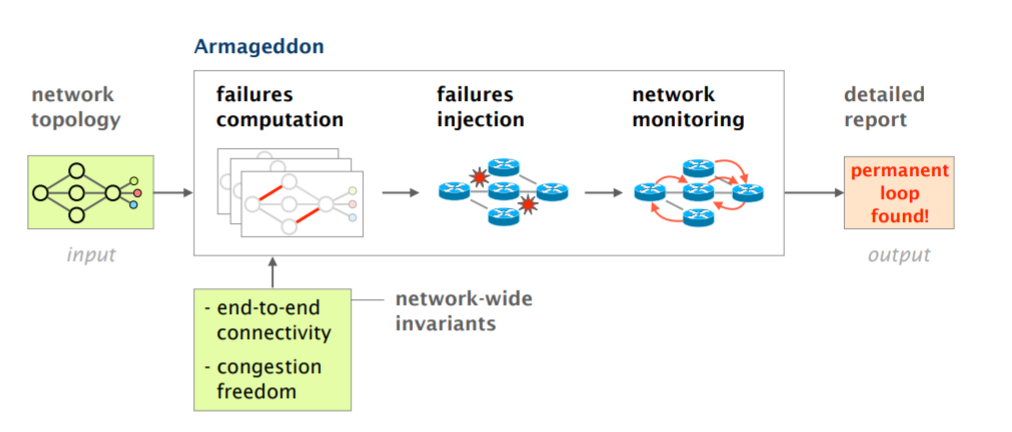
Network failures are inevitable. Interfaces go down, devices crash and resources become exhausted. It is the responsibility of the control software to provide reliable services on top of unreliable components and throughout unpredictable events. Guaranteeing the correctness of the controller under all types of failures is therefore essential for network operations. Yet, this is also an almost impossible task due to the complexity of the control software, the underlying network, and the lack of precision in simulation tools. Instead, we argue that testing network control software should follow in the footsteps of large scale distributed systems, such as those of Netflix or Google, which deliberately induce live failures in their production environments during working hours, and analyze how their control software reacts. In this paper, we describe Armageddon, a framework for introducing sustainable and systematic chaos in networks. When we cause failures, we do so without violating some operator-specified network invariants (e.g., end-to-end connectivity). The injected failures also guarantee some notion of coverage. If the controller can sustain all of the failures, then it can be considered resilient with a high degree of confidence. We describe efficient algorithms to compute failure scenarios and implemented them in a prototype. Applied to real-world networks, our algorithms a coverage of 80% of the links within only three iterations of failures.
 Top
Top
- Shelly, Nick
- Tschaen, Brendan
- Foerster, Klaus-Tycho
- Chang, Michael
- Benson, Theophilus
- Vanbever, Laurent
Top
Category |
Paper in Conference Proceedings or in Workshop Proceedings (Paper) |
Event Title |
14th ACM Workshop on Hot Topics in Networks (HotNets 2015) |
Divisions |
Communication Technologies |
Subjects |
Rechnerperipherie, Datenkommunikationshardware |
Event Location |
Philadelphia, USA |
Event Type |
Conference |
Event Dates |
16-17 Nov 2015 |
Date |
November 2015 |
Export |
Top
